Deepfake Detection Using Vision Transformers and Explainable Artificial Intelligence for Secure Multimedia Authentication
Keywords:
Deepfake Detection, Vision Transformers, Explainable Artificial Intelligence, Multimedia Authentication, Adversarial ForensicsAbstract
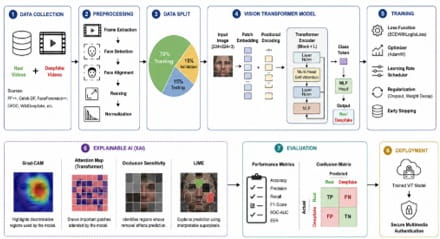
The rapid advancement of generative artificial intelligence and deep learning technologies has significantly accelerated the creation of highly realistic synthetic multimedia content, commonly referred to as deepfakes. Deepfake technologies utilize advanced neural architectures such as Generative Adversarial Networks (GANs), autoencoders, and diffusion models to manipulate facial expressions, voice characteristics, lip synchronization, and visual identities within digital media. Although these technologies provide beneficial applications in entertainment, virtual reality, education, and digital communication, they also introduce serious cybersecurity, privacy, and misinformation challenges. Deepfakes are increasingly used for identity theft, political misinformation, financial fraud, cyber deception, social engineering attacks, fake news propagation, and unauthorized multimedia manipulation. Traditional multimedia authentication techniques frequently fail to accurately identify sophisticated deepfake content because of rapidly evolving generative models and highly realistic synthetic visual representations. This research proposes a Deepfake Detection Framework Using Vision Transformers and Explainable Artificial Intelligence for Secure Multimedia Authentication. The proposed framework integrates Vision Transformer (ViT)-based spatial-temporal feature extraction, attention-driven multimedia representation learning, explainable artificial intelligence (XAI), adversarial forensic analytics, and adaptive classification optimization to support robust and interpretable deepfake detection across heterogeneous multimedia environments. The framework continuously analyses facial inconsistencies, temporal anomalies, attention distributions, synthetic texture artifacts, and semantic manipulation patterns to identify manipulated multimedia content with high precision and reliability.